Toptal
Supervised learning has been at the forefront of research in computer vision and deep learning over the past decade.
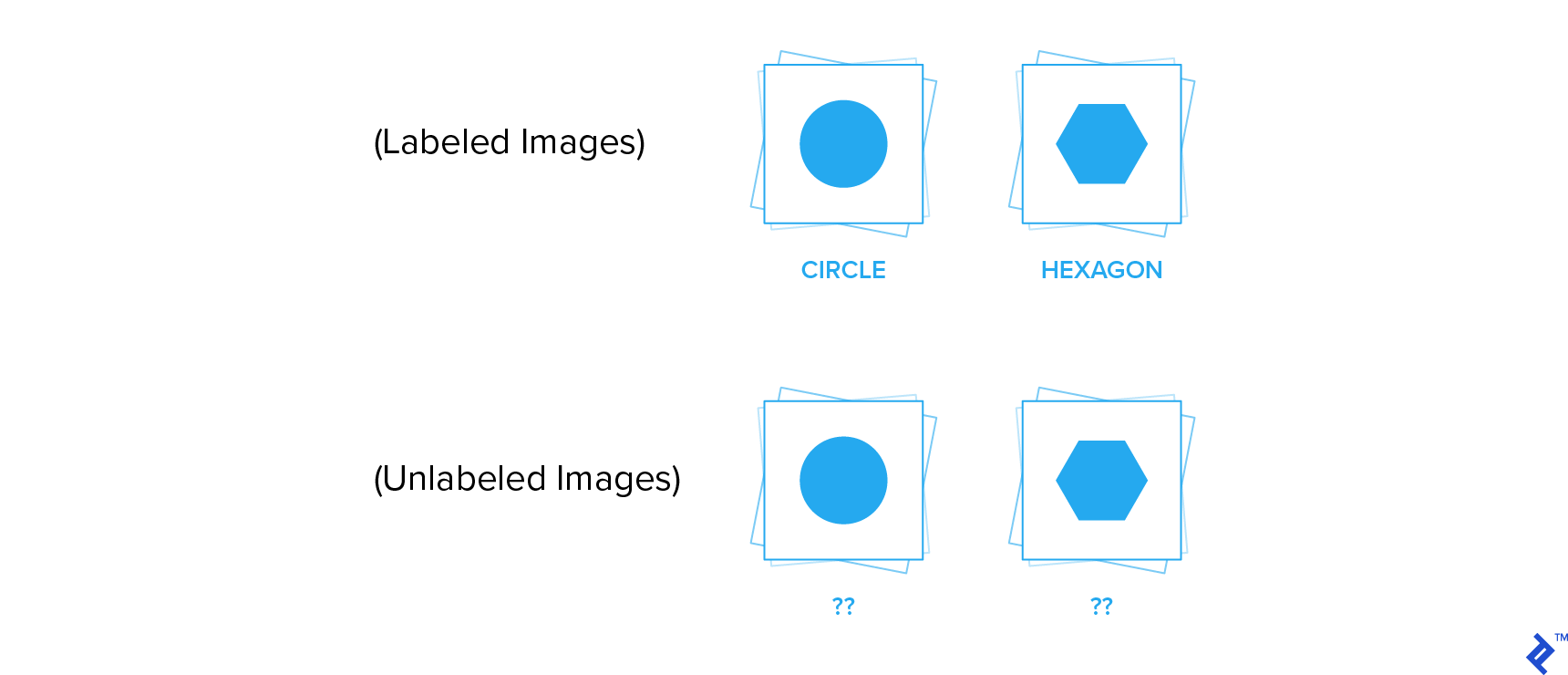
In a supervised learning setting, humans are required to annotate a large amount of dataset manually. Then, models use this data to learn complex underlying relationships between the data and label and develop the capability to predict the label, given the data. Deep learning models are generally data-hungry and require enormous amounts of datasets to achieve good performance. Ever-improving hardware and the availability of large human-labeled datasets has been the reason for the recent successes of deep learning.
One major drawback of supervised deep learning is that it relies on the presence of an extensive amount of human-labeled datasets for training. This luxury is not available across all domains as it might be logistically difficult and very expensive to get huge datasets annotated by professionals. While the acquisition of labeled data
To read the full article click on the 'post' link at the top.